Introduction
Overview
Teaching: 25 min
Exercises: 5 minQuestions
What is a parallel computer?
What parallel programming models are there?
How do I get performance?
Objectives
Understand how computers can be used to perform parallel calculations
Understand the difference between shared and distributed memory
Use memory correctly to get higher performance.
Terminology
Hardware
- CPU = Central Processing Unit
- Core = Processor = PE (Processing Element)
- Socket = Physical slot to fit one CPU.
- Node = In a computer network typically refers to a host computer.
Software
- Process (Linux) or Task (IBM)
- MPI = Message Passing Interface
- Thread = some code / unit of work that can be scheduled
- OpenMP = (Open Multi-Processing) standard for shared memory programming
- User Threads = tasks * (threads per task)
A CPU is a computer’s Central Processing Unit that is in charge of executing the instructions of a program. Modern CPUs contain multiple cores that are physical independent execution units capable of running one program thread. CPUs are attached to a computer’s motherboard via a socket and high-end motherboards can fit multiple CPUs using multiple sockets. A group of computers (hosts) linked together in a network conform a cluster in which each individual computer is referred as a node. Clusters are typically housed in server rooms, as is the case for Hawk supercomputer located at the Redwood Building in Cardiff University.

Why go parallel?
Over time the number of cores per socket have increased considerably, making parallel work on a single computer possible and parallel work on multiple computers even more powerful. The following figure shows the change in market share of number of Cores per Socket as a function of time. In the early 2000’s it was more common for systems to have a single core per socket and just a few offered a dual core option. Fast forward to late 2019 and the landscape has changed a lot with several options now available. Systems with 20 cores per socket represented 35% of the market (as with Hawk’s Skylake CPUs) while systems with 32 cores per socket represented only 1.2% (as with Hawk’s AMD Epyc Rome CPUs). Will this trend continue? It is likely, and therefore, it is worth investing in learning how parallel software works and what parallelization techniques are available.

Single computers

A Central Processing Unit, or CPU, is a piece of hardware that enables your computer to interact with all of the applications and programs installed in a computer. It interprets the program’s instructions and creates the output that you interface with when you’re using a computer. A computer CPU has direct access to the computer’s memory to read and write data necessary during the software execution.
As CPUs have become more powerful, they have allowed to develop applications with more features and capable of handling more demanding tasks, while users have become accustomed to expecting a nearly instantaneous response from heavy multitasking environments.
Make it go faster
When we talk about a computer’s speed, we typically are referring to its performance when interacting with applications. There are three main factors that can impact a computer’s performance:
-
Increase clock speed : Clock speed refer to the number of instructions your computer can process each second and is typically measured in GHz, with current gaming desktop computers in the order of 3.5 to 4 GHz.
-
Increase the number of CPUs : Ideally, we would like to have the best of both worlds, as many processors as possible with clock speed as high as possible, however, this quickly becomes expensive and limiting due to higher energy demand and cooling requirements.
-
Available vector instructions: Modern CPUs are equipped with the capacity to apply the same instruction to multiple data points simultaneously, this is known as SIMD instructions.
Did you know?
Hawk has two types of CPUs available:
- Xeon Gold 6148 (Skylake) at 2.4GHz clock speed, 20 cores per node and support for AVX512 instructions.
- AMD Epyc Rome 7502 at 2.5 GHz clock speed, 32 cores per node and support for AVX256 instructions.
Find out more here: SCW Portal
Parallel computers

Since Intel Pentium 4 back in 2004, which was a single core CPU, computers have gradually increased the number of cores available per CPU. This trend is pushed forward by two main factors: 1) a physical limit to the number of transistors that can be fit in a single core, 2) the speed at which these transistors can change state (on/off) and the related energy consumption.
Reducing a CPU clock speed reduces the power consumption, but also its processing capacity. However, since the relation of clock speed to power consumption is not linear, effective gains can be achieved by adding multiple low clock speed CPUs.
Although CPU developers continue working towards increasing CPU clock speeds by engineering, for example, new transistor geometries, the way forward to achieve optimal performance is to learn to divide computations over multiple cores, and for this purpose we could keep in mind a couple of old sayings:
“Many hands make light work”
“Too many cooks spoil the broth”
Amdahl’s Law
Amdahl’s Law places a strict limit on the speedup that can be realized by using multiple processors. For example time using n processors is tn and fraction of code that is parallel, fp, and fraction of code that is serial, fs can be shown to be:
This can be rearranged to give relative speedup S:
What is the limit if code is 100% parallel? What happens if you throw infinite number of processors at a problem with non-zero serial fraction of code.?
Solution
- If fs is zero then speedup is equal to number of processors n.
- If n approaches infinity, speedup is 1/fs. If only 1% of code is serial, you cannot get speedup of more than 100.


Thinking about programming
- Decompose the problem
- Divide the algorithm (car production line) - Breaking a task into steps performed by different processor units.
- Divide the data (call centre) - If well defined operations need to be applied on independent pieces of data.
- Distribute the parts
- work in parallel
- Considerations
- Synchronisation
- Communicate between processor
- Hardware issues
- What is the architecture being used?
Shared memory

As the name suggests, shared memory is a kind of physical memory that can be accessed by all the processors in a multi CPU computer. This allows multiple processors to work independently sharing the same memory resources with any changes made by one processor being visible to all other processors in the computer.
OpenMP is an API (Application Programming Interface) that allows shared memory to be easily programmed. With OpenMP we can split the work of the calculation by dividing the work up among available processors. However, we need to be careful as to how memory is accessed to avoid potential race conditions (e.g. one processor changing a memory location before another has finished reading it).
Distributed memory

In comparison with shared memory systems, distributed memory systems require network communication to connect memory resources in independent computers. In this model each processor runs its own copy of the program and only has direct access to its private data which is typically a subset of the global data. If the program requires data to be communicated across processes this is handled by a Message Passing Interface in which, for example, one processor sends a message to another processor to let it know it requires data in its domain. This requires a synchronization step to allow all processors send and receive messages and to prepare data accordingly.
How it works?
A typical application is to parallelize matrix and vector operations. Consider the following example in which a loop is used to perform vector addition and multiplication. This loop can be easily split across two or more processors since each iteration is independent of the others.
DO i = 1, size
E(i) = A(i) + B(i)
F(i) = C(i) * D(i)
END DO
Consider the following figure. In a shared memory system all processors have access to a vector’s elements and any modifications are readily available to all other processors, while in a distributed memory system, a vector elements would be decomposed (data parallelism). Each processor can handle a subset of the overall vector data. If there are no dependencies as in the previous example, parallelization is straightforward. Careful consideration is required to solve any dependencies, e.g. A(i) = B(i-1) + B (i+1).

Approaches to decomposition
The approach to decomposition sets the model for the whole code since it will decide how and when communication is performed. Try to minimise dependencies between decomposed regions, try and make the load balanced, and change decomposition depending on problem.
Once the decision has been made to decompose, writing the code to communicate when needed (either gathering or distributing data). For example, in a weather and climate model you may have haloes of data from neighbouring processors to keep a snapshot of data you may need. If data is changed in regions other processors may have the data in a halo an exchange of haloes may need to take place.
When communicating, the edge points need special attention. For a weather and climate model this may mean the polar regions on a latitude/longitude grid need special attention.
Communication!!!
Efficient communication is key to reducing network traffic and using the performance on the local machine as much as possible.
For example, an equation may be the following
new(i,j) = 0.5 * ( old(i-1,j) + old(i+1,j) )
If we were to split in the i direction, it would lead to commuication. In the j direction it would require no communication.
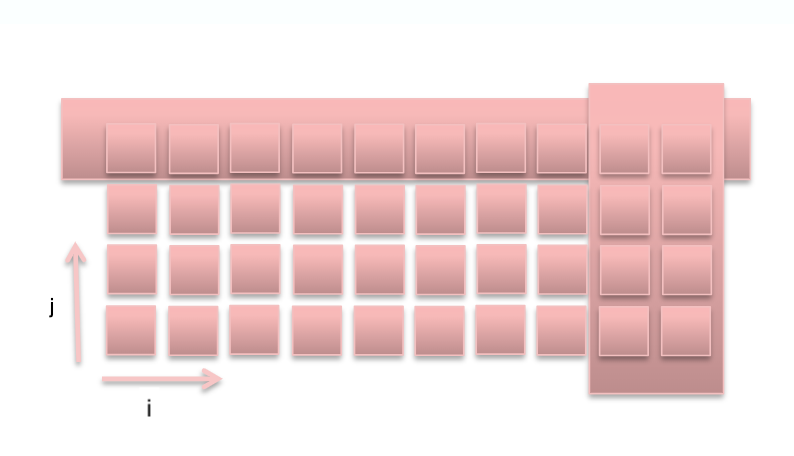
The balancing act
In practice, highly optimized software tends to use a mixture of distributed and shared memory parallelism called “hybrid” where the application processes use shared memory within the node and distributed memory across the network.
The challenge is to balance the load across the nodes and processors giving enough work to everyone. The aim is to keep all tasks busy all the time since an idle processor is a waste of resources.
Load imbalances can be caused, for example:
- by array dimensions not being equally divided. Compilers can address these issues through optimization flags, that allow, for example, to collapse loops, changing a matrix A(m,n) to a vector A(n*m) that is easier to distribute.
- Different calculations for different points – e.g. different governing equations applied to sea or land points on a weather forecasting model.
- The amount of work each processor need to do cannot be predicted - e.g. in adaptive grid methods where some tasks may need to refine or coarse their mesh and others don’t.
Granularity
Granularity refers in parallel computing to the ratio between communication and computation, periods of computation are separated by periods of communication (e.g. synchronization events).
There are two types of approaches when dealing with load balancing and granularity parallelization:
-
“Fine-grain” - where many small workloads are done between communication events. Small chunks of work are easier to distribute and thus help with load-balancing, but the relatively high number of communication events cause an overhead that gets worse as number of processors increase.
-
“Coarse-grain” - where large chunks of workload are performed between communications. It is more difficult to load-balance but reduces the communication overhead
Which is best depend on the type of problem (algorithm) and hardware specifications but in general a “Coarse-grain” approach due to its relatively low communication overhead is considered to have the best scalability.
Steps to parallel code
- Familiarize with the code and identify parts which can be parallelized
- This typically requires high degree of understanding
- Decompose the problem
- Functional (shared) or data (distributed), or both
- Code development
- Choose a model to concentrate on
- Data dependencies
- Divide code where for task or communication control
- Compile, Test, Debug, Optimize
Key Points
MPI is one of many ways to take advantage of parallel computers.
Many different strategies to parallel programming.
Use the most appropriate strategy for your problem.
MPI standard
Overview
Teaching: 25 min
Exercises: 5 minQuestions
Why was MPI developed?
How can I use MPI?
What is the basic code required?
Objectives
Understand why MPI is important
Understand how MPI can be coded
Use the key MPI functions to write a basic example
A brief history
The idea of message passing evolved in the 1980s where supercomputers were dominated by Cray. Due to dependency on Cray and competition was difficult this required new approaches to supercomputing. Message passing was born out of a desire to link competing technologies. Cray realised that many cheaper commodity processors could be linked together cheaper than fewer expensive vector processors. To make sure code was portable between systems, assurances were made to make this possible hence MPI was formed.
MPI forum was formed in 1992 with its first standard in 1994, available in C and Fortran. The easiest approach was to decompose data for processors to work on the same problem (but different views). This works within processors on a node and across a network and is Limited only by Amdahl’s Law.
MPI standard is large, but the good news is that many programs only use a small subset. There are many sophisticated functions available. The design of MPI makes no assumptions on underlying hardware so work with homogenous and heterogeneuos systems, that is to say it is hardware vendor neutral.
ECMWF weather and climate model IFS
A well respected weather and climate model called IFS, developed by the European Centre for Medium-range Weather Forecasting, ECMWF, only required approximately 10 MPI calls.
Preliminary information
The examples are written in Python using the mpi4py module. This should be easily translated into other languages. The web can be used for information.
Data models
- SPMD - Single Program Multiple Data is usually the recommended approach.
- One program executes mutliple times.
- Problem divided using the same executable code.
- MPMD - Multiple Program Multiple Data can be trickier to master.
- Different executables used to communicate
- Useful to couple different models that would contain completely different approaches such as ocean and atmosphere modelling.
- Available in MPI version 2.0
Definitions
- Task
- One running instance of program
- Basic unit of MPI parallel code
- Leader
- The first task in the set of parallel tasks
- Given id of zero
- Follower
- All other tasks in the program.
- No real difference other than usually leader can interact easily with system, such as I/O.
Hello World!
The following command executes a 3 MPI tasks.
$ mpirun -np 3 echo "hello_world"
hello_world
hello_world
hello_world
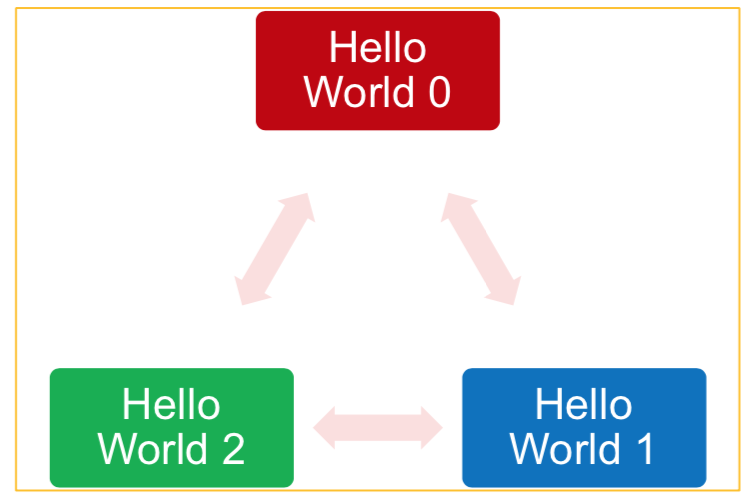
A more meaningful hello world program may be written as:
#!/bin/env python
#
# Hello World MPI
from mpi4py import MPI # Python MPI library
import sys
if __name__ == "__main__":
# What rank process is this?
try:
comm = MPI.COMM_WORLD # Initiate communications
rank = comm.Get_rank()
size = comm.Get_size()
# Say hello
print(f"Hello World from process: {rank} of {size}")
except Exception as err:
sys.exit("Error: %s" % err)
Then run in SLURM with:
#!/bin/bash --login
#SBATCH -p compute
#SBATCH --account=scw1148
#SBATCH --ntasks=3
#SBATCH --tasks-per-node=3
#SBATCH -o HelloPython.out
#SBATCH -t 00:05:00
# Load required modules. module purge
module load python
module load mpi
# Run 3 (mpirun knows SLURM variables) copies of the code
mpirun python3 hello_parallel.py
Initialisation and identification
The MPI standard defines the following.
MPI_initandMPI_init_thread- initialises MPI environment. Required by MPI standard.MPI_COMM_WORLD- a provided communicator that allows all processors to “talk” to all others.MPI_comm_size- a function that returns the total number of processors in communicator.MPI_comm_rank- a function that returns the id of the current exectuable within the communicator.MPI_finalize- a function that shuts down MPI communications - the counterpart toMPI_init.
In Python these are used behind the scenes to perform similar functionality but in a Pythonic manner. For example
at import time the MPI_init_thread is called. At exit MPI_finalize is called automatically. The MPI_comm_rank and
MPI_comm_size functions are called in the mpi4py communicator methods Get_rank and Get_size.
The MPI Python module
- mpi4py is the top-level package.
- provides package MPI
- contains all the MPI constructs and parameters.
- encapsulates the MPI protocol in wrapper functions to allow passing of python objects not coverred by the MPI standard.
Install the package on Hawk/Linux
Since this is a Python package, anyone should be able to download and install the package. How would you go about doing this? (Hint: Look at previous SLURM Advanced Topics
Solution
There is a dependency on MPI so you would need to load the mpi module. The Python package will already load a compiler. Check
module listafter loading modules.To install mpi4py:
$ module load python $ module load mpi $ python3 -m venv venv $ . venv/bin/activate $ pip install -U pip $ pip install mpi4py $ python3 -c "import mpi4py"
Other platforms
Each platform would have a way to install Python modules to work with MPI.
Key Points
MPI allowed programmers to write portable code across many different supercomputer architectures.
MPI is available is available in many languages.
MPI requires function calls to pass data around.
MPI point to point communication
Overview
Teaching: 45 min
Exercises: 15 minQuestions
How do I send a message?
How do I know if it was successful?
Objectives
Understand how to send a message
Know when to use blocking and non-blocking communication.
The first type of communication in MPI is called “Point to Point” where you have some data and know which other MPI task to send and receive from.
Refresher
Check you understand what
MPI_Init,MPI_COMM_WORLD,MPI_comm_rankandMPI_comm_sizeare.
MPI_initandMPI_init_thread
- Initialises MPI environment inside code.
- Strictly speaking code before this is called has undefined behaviour.
- Function automatically called by
mpi4pylibrary.- Capture the error messages from this function.
MPI_COMM_WORLD
- MPI communicator representing a method to talk to all processors.
- The
mpi4pylibrary represents this withMPI.COMM_WORLD- Having different communicators is quite advanced.
- This is most common communicator to use.
MPI_comm_size
- Function that returns the size of the communicator.
- The
mpi4pylibrary represents this in a class method Get_size()- Stops having to read number of processors from elsewhere.
- For
MPI_COMM_WORLDit should return the number of processors.- Allows for dynamic allocation of resources without recompiling or relying on hard-coded arrays.
MPI_comm_rank
- An identifier within the communicator between
0andMPI_comm_size-1- The
mpi4pylibrary represents this in a class method Get_rank()- Can be confusing in Fortran as arrays are usually indexed from 1.
- Used as part of the address when communicating messages.
MPI_finalize
- Tells the MPI layer we have finished.
- Any MPI calls after this will be an error.
- Does not stop the program.
- Usually called near (or at) the end.
- The
mpi4pylibrary calls this automatically when exiting.- Alternatively
MPI_abortcan be used
- Aborts task in communicator
- One processor may cause the abort.
- Should only be used for unrecoverable error.
mpi4pycan perform this automatically with unhandled exceptions in Python using-m mpi4pymethod of running.
Basics
Before code is written to perform communication, lets revisit a simple “Hello World” example.
Hello World
Create a simple MPI program that does the following:
- Loads the
mpi4pymodule- Gets the rank of the MPI task.
- Gets the maximum number of the MPI tasks.
- Print message including its rank.
- Leader task only prints the maximum number of tasks.
Solution
Example code available hello_parallel.py Important lines are:
from mpi4py import MPIcomm = MPI.COMM_WORLDrank = comm.Get_rank()size = comm.Get_size()if rank == 0:
To run the code you can use as a basis hello_parallel-slurm.sh
MPI_Send and MPI_Recv
The first type of communication is using a blocking send and receive. This will not process any further code until the
send has been completed (i.e. why it is described as blocking). With mpi4py we can use comm.send and comm.recv.
A message is just identifiable data on the network:
- Think of it as an envelope
- Various datatypes can be used inside this envelope
- Python objects are serialized into standard datatypes.
- Data length can be zero to many MBs.
- Messages can have tag identifiers to further identify them.
The send and receives have to work in partnership. Without a receive to pick up the data from the (blocking) send the code will hit a deadlock with the code not able to progress with both MPI tasks waiting for their communications to complete. Therefore every send must have a receive (and vice-versa).
There is also a special MPI_ANY_SOURCE to receive from any sender.
Tagging
Tags allow messages to be further identified and can be used to make messages read in the correct order. There is no guarantee messages arrive in the order they were sent. Tags can have any value but ideally should be identifiable uniquely so errors in communication can be traced if the tag number is given.
A special tag identifier MPI_ANY_TAG can ignore tag number.
Python interface
The mpi4py interface to MPI_Send and MPI_Recv is with the following:
comm.send(data, dest=?, tag=?)
data = comm.recv(source=?, tag=?)
Exchanging odd with even
Lets use the knowledge of sending and receiving data by exchanging data between pairs of MPI tasks.
- Each pair will exchange data with each other
- Tasks with an even rank number will send data to
rank+1- Tasks with an odd rank number will send data to
rank-1Solution
The key thing is to make sure one of the pairs (either the odd or even) send the data first whilst the other pair waits to receive the data. See point.py and the corresponding slurm job script.
Non-blocking
A standard send or receive will block waiting for the operation to complete and can cause deadlocks. The non-blocking versions are very similar but need to be careful to wait for communication to complete before using the data location. For example to send:
req = comm.isend(data, dest=1, tag=11)
req.wait()
Whilst to receive:
req = comm.irecv(source=0, tag=11)
data = req.wait()
Notice the wait() method is used to declare when the code should wait for completion. Useful for exchanging data if
sending and receiving at the same time.
Non-blocking communication
Try revisiting the previous example of sending data between pairs of processors. How can this be done with non-blocking communication?
Solution
The key difference is the sends and receives do not need to be different (no matching send to a receive in order this time. Just
isendandirecvand thenwaitfor the sends to complete and then receive the data.Check out the point_nonblock.py and the corresponding slurm job script.
Synchronize
Now that it is possible to communicate between MPI tasks. It is sometimes useful to make sure all MPI tasks are at the same location in the code. Could be used for:
- timing locations in the code
- tidy up the output from the code.
A task enters MPI_Barrier and waits for all other MPI tasks to reach the same location in the code. If an MPI task
does not reach the barrier then a deadlock will occur.
In mpi4py this is achieved with comm.barrier(). For example
from mpi4py import MPI
import time
comm = MPI.COMM_WORLD
id = comm.Get_rank()
time.sleep(id)
comm.barrier()
print(f"Hello from rank {id}", flush=True)
time.sleep(id)
comm.barrier()
print(f"Bye from rank {id}", flush=True)
With comm.barrier():
Hello from rank 0
Hello from rank 1
Hello from rank 2
Hello from rank 3
Bye from rank 3
Bye from rank 0
Bye from rank 1
Bye from rank 2
Without comm.barrier():
Hello from rank 0
Bye from rank 0
Hello from rank 1
Hello from rank 2
Bye from rank 1
Hello from rank 3
Bye from rank 2
Bye from rank 3
It should be noted that synchronization points such as MPI_Barrier can waste resource and harm scalability since some
MPI tasks might be waiting in the barrier not doing any work.
Identification
It is sometimes useful to know where your MPI task is running - imagine a 1000 MPI task job across a number of servers - how do we identify which server the MPI task was on?
With MPI_Get_processor_name is it possible to obtain a unique string to identify the server/resource it is running on.
In mpi4py it is called with:
from mpi4py import MPI
MPI.Get_processor_name()
Optimizing communication
In mpi4py there are multiple ways to call the same method due to its automatic handling of Python datatypes such as
dictionaries and lists. These calls tend to start with a lowercase as in the examples above, e.g. comm.irecv but to
gain some speedup there are the direct C-style functions called with uppercase, e.g. comm.Irecv and expects the
buffers to be passed as an argument as in comm.Irecv([buffer, MPI_INT], source=0, tag=0). Note the buffer is now in
n list with the second entry the MPI datatype of the buffer. This speeds up commnicatation rather than mpi4py
converting all buffers with raw bytes with pickle but can only be used for MPI standard types.
When using numpy arrays, the datatype of the arrays is stored with the data and therefore mpi4py can query the
datatype and specify the correct MPI datatype in the communication. This only supports standard numpy C datatypes.
To keep things simple we will use the lowercase variant that supports all types.
Further information
Please check mpi4py documentation site. Especially the tutorial secion.
Key Points
Sending messages to another processor is like sending a letter.
Non-blocking is most flexible type of point to point communication - just make sure you check for completion.
MPI collective communication
Overview
Teaching: 45 min
Exercises: 15 minQuestions
How do I avoid having to use multiple recvs and sends?
What operations can be performed by all processors at once?
Objectives
Understand what are collective communications
Benefit from optimizations in commnication patterns
The previous section coverred the topic of point to point communication where a message can be sent from one MPI task to another. Although these are the building blocks of MPI there are a number of common communication patterns that are provided within the MPI standard. The collective communications are when all MPI tasks can be involved in a single function call. This replaces multiple calls to recv and send, easier to understand and provides internal optimisations to communication.
Broadcasting
If a MPI task requires data to be send to all processors then MPI_Bcast can be used to make sure this occurs. It is a
very basic sending of data from a single MPI task with all the other MPI tasks receiving the data. In mpi4py it is
achieved with:
comm.Bcast([buffer, MPI_INT], root=0)
Or with the general-purpose method:
buffer = comm.bcast(buffer, root=0)
Where buffer is the the data to be broadcast for the MPI task given as root (in this case 0). The MPI datatype is
optional and automatic discovery can be used instead with the lowercase method name.
Scattering and gathering
If data needs to be shared across processors to decompose the problem into a small subset it can be performed with
MPI_Scatter. When the data needs to be collected again on an MPI task the gather function MPI_Gather can be used.
In mpi4py this is achieved with:
recvbuffer = comm.scatter(sendbuffer, root=0)
recvbuffer = comm.gather(sendbuffer, root=0)
For scatter, sendbuffer is defined on MPI task 0 whilst for gather recvbuffer returns a value only on MPI task 0.
There are also the uppercase comm.Scatter and comm.Gather along with non-blocking variants comm.Iscatter and
comm.Igather that has to be provided with datatypes of the data (or using numpy arrays).
Further scattering and gathering
Scatter and gather are the building blocks for many other types of communication patterns with the only difference being where we want the results to reside.
Gather-like
MPI_Allgather- gather one array onto all tasks.comm.allgatherorcomm.AllgatherMPI_Gatherv- gather arrays of different lengths onto a task.comm.gathervorcomm.GathervMPI_Allgatherv- gather arrays of different lengths onto all tasks.comm.allgathervorcomm.Allgatherv
Scatter-like
MPI_Scatter- scatter one array onto all tasks.comm.scatterorcomm.ScatterMPI_Scatterv- scatter array into different lengths onto all tasks.comm.scattervorcomm.Scatterv
All-to-all
MPI_Alltoall- every task sends equal length parts to all other tasks.comm.alltoallorcomm.AlltoallMPI_Alltoalllv- every task sends unequal length parts to all other tasks.comm.alltoallvorcomm.Alltoallv
There are also the non-blocking versions of all communication, e.g. MPI_Iallgather where mpi4py provides
comm.Iallgather.
Scatter example
Scatter a chunk of data using collective functions in
mpi4py. Each processor should be provided with 2 chunks of the data from the MPI task performing the scatter.Should we use
comm.Scatterorcomm.scatter?Solution
In this example we fix the size of the array to scatter as
nprocs, the size of the communicator (number of MPI tasks).if rank == 0: senddata = [(x+1)**x for x in range(nprocs)] print('we will be scattering:',senddata) else: senddata = NoneWhen scattering the data the receiving array is sized to be just
allosize.recvdata = [None] recvdata = comm.scatter(senddata, root=0)See the example in scatter.py and the corresponding slurm job script.
Reduction
A reduction allows for an operation to be performed on data as it is being communicated. MPI_Reduce allows for this
operation to occur with the result returned on one MPI task. mpi4py provides comm.reduce or comm.Reduce. The supported operations can be:
MPI_MAX- Returns the maximum element.MPI_MIN- Returns the minimum element.MPI_SUM- Sums the elements.MPI_PROD- Multiplies all elements.MPI_LAND- Performs a logical and across the elements.MPI_LOR- Performs a logical or across the elements.MPI_BAND- Performs a bitwise and across the bits of the elements.MPI_BOR- Performs a bitwise or across the bits of the elements.MPI_MAXLOC- Returns the maximum value and the rank of the process that owns it.MPI_MINLOC- Returns the minimum value and the rank of the process that owns it.
The mpi4py equivalents are part of the MPI module, for example MPI_MAX is MPI.MAX.
If the result is required on all MPI tasks then MPI_Allreduce is used instead. This would be similar to a
MPI_Reduce followed by a MPI_Bcast.
Beware!
Reductions can produce issues. With floating-point numbers a reduction can occur in any order and therefore summations are non-reproducible. This means every time you run the code it may give different answers and also across different number of processors. If reproducibility is important then one way is to gather all the data to a single MPI task and perform the operation in a controlled manner - this would harm performance. If you do not need reproducibility across different number of processors then summation on each processor and then reduce might be better.
Sine Integral
Using the above collectives obtain the integral of
sin(x).
- broadcast the number of points being used.
- each MPI task calculates the region it needs to do.
- perform the calculation on its range.
- use the
MPI_Reducemethod to sum the data.Can you think of other ways of doing this?
Solution
Lets assume rank 0 only knows the value of numpoints (read from configuration file or stdin).
if rank == 0: recvbuffer = np.array(numpoints) else: recvbuffer = np.array(0) comm.Bcast([recvbuffer, MPI.INT], root=0)Next calculate the range the MPI task should use.
nlocal = (numpoints - 1) / nprocs + 1 nbeg = int((rank * nlocal) + 1) nend = int(min((nbeg + nlocal - 1), numpoints))Perform the integration
for i in range(nbeg, nend): psum += np.sin((i - 0.5) * delta) * deltaFinally perform a reductin on all the local summations on each MPI task
resbuffer = np.array(0.0, 'd') comm.Reduce([psum, MPI.DOUBLE], resbuffer, op=MPI.SUM, root=0)For the complete solution see sine.py and the corresponding slurm job script.
Key Points
Collective communications make the code easier to understand the purpose.
Advanced topics in MPI
Overview
Teaching: 30 min
Exercises: 15 minQuestions
What is the best way to read and write data to disk?
Can MPI optimise commnications by itself?
How can I use OpenMP and MPI together?
Objectives
Use the appropriate reading and writing methods for your data.
Understand the topology of the problem affects communications.
Understand the use of hybrid coding and how it interacts.
Having coverred simple point to point communication and collective communications, this section covers topics that are not required but useful to know exist.
MPI-IO
When reading and writing data to disk from a program using MPI, there are a number of approaches:
- gather/scatter all data to/from leader (MPI task 0) and write/read to disk from this one task. Performance can be slow to communicate and perform a large amount of I/O from one task.
- read and write directly to disk from each MPI task but to separate files. Not good for portability due to dependent on processor decomposition.
- use included MPI-IO that takes advantage of parallel filesystems performane and knowledge of where MPI task should read or write data.
All forms of MPI-IO require the use of MPI_File_Open. mpi4py uses:
MPI.File.Open(comm, filename, amode)
Where amode is the access mode - such as MPI.MODE_WRONLY, MPI.MODE_RDWR, MPI.MODE_CREATE. This can be combined
with bitwise-or | operator.
There are 2 types of I/O, independent and collective. Independent I/O is like standard Unix I/O whilst Collective I/O is where all MPI tasks in the communicator must be involved in the operation. Increases the opportunity for MPI to take advantage of optimisations such as large block I/O that is much more efficient that small block I/O.
Independent I/O
Just like Unix like open, seek, read/write, close. MPI has a way of allowing a single task to read and write
from a file.
MPI_File_seek- seek to positionMPI_File_read- read from a task.MPI_File_write- write from a task.MPI_File_read_at- seek and read from task.MPI_File_write_at- seek and read from task.MPI_File_read_shared- read using shared pointerMPI_File_write_shared- write using shared pointer
mpi4py have its similar versions e.g. File.Seek - see help(MPI.File)
For example to write from the leader:
from mpi4py import MPI
import numpy as np
amode = MPI.MODE_WRONLY|MPI.MODE_CREATE
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
fh = MPI.File.Open(comm, "./datafile.mpi", amode)
buffer = np.empty(10, dtype=np.int)
buffer[:] = rank
offset = comm.Get_rank() * buffer.nbytes
if rank == 0:
fh.Write_at(offset, buffer)
fh.Close()
Useful where collective calls do not naturally fit in code or overhead of collective calls outweigh benefits (e.g. small I/O). You can find an example in mpiio.independent.py and its corresponding mpiio.independent-slurm.sh.
Collective non-contiguous I/O
If a file operation needs to be performed across the whole file but not contigious (e.g. gaps between data that the each
task reads). This uses the concept of a File view set with MPI_File_set_view. mpi4py uses fh.Set_view where
fh is the file handle returned from MPI.File.Open.
fh.Set_view(displacement, filetype=filetype)
displacement is the location in the file and filetype is a description of the data for each task.
Key functions are:
MPI_File_seek- seek to positionMPI_File_read_all- read across all tasks.MPI_File_write_all- write across all tasks.MPI_File_read_at_all- seek and read all tasks.MPI_File_write_at_all- seek and read all tasks.MPI_File_read_ordered- read using shared pointerMPI_File_write_ordered- write using shared pointer
The _at_ versions of the functions are better than performing a seek and then an read or write. See help(MPI.File)
For example:
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
amode = MPI.MODE_WRONLY|MPI.MODE_CREATE
fh = MPI.File.Open(comm, "./datafile.noncontig", amode)
item_count = 10
buffer = np.empty(item_count, dtype='i')
buffer[:] = rank
filetype = MPI.INT.Create_vector(item_count, 1, size)
filetype.Commit()
displacement = MPI.INT.Get_size() * rank
fh.Set_view(displacement, filetype=filetype)
fh.Write_all(buffer)
filetype.Free()
fh.Close()
You can find an example in mpiio.non.contiguous.py and its corresponding mpiio.non.contiguous-slurm.sh.
Contiguous collective I/O
Contiguous collective I/O is where all tasks are used to perform the I/O operation across the whole data.
Contiguous example
Write a file where each MPI task write 10 elements with value of its rank in order of rank.
Solution
This is very similar to the non-contiguous I/O but the file view is not required.
offset = comm.Get_rank() * buffer.nbytes fh.Write_at_all(offset, buffer)
You can find an example in mpiio.collective.py and its corresponding mpiio.collective-slurm.sh.
Access patterns
Access patterns can greatly impact the performance of the I/O. It is expressed with 4 levels - level 0 to level 3.
- Level 0, each process makes one independent read request for each row in the local array.
- Level 1, similar to leve 1 but collective I/O functions are used.
- Level 2, process creates a derived filetype using non-contiguous access pattern and calls independent I/O functions.
- Level 3, similar to level 2 but each process uses collective I/O functions.
In summary MPI-IO requires some special care but worth looking at closer if you have large data access requirements in your code. Level 3 would give the best performance.
Application toplogies
MPI tasks have no favoured orientation or priority, however it is possible to map tasks onto a virtual topology. The topologies are:
- Cartesian, a regular grid
- Graph, a more complex connected structure.
The functions used are:
MPI_Cart_Create- creates a Cartesian topology from specified communicatorMPI_Cart_Get- returns information about a given topologyMPI_Cart_Rank- return rank from Cartesian locationMPI_Cart_Coords- return coordinates for a task of a given rankMPI_Cart_Shift- discover rank of near neighbour given a shifted direction. i.e. Up, Left, etc.
In mpi4py to create a Cartesian toplogy:
cart = comm.Create_cart(dims=(axis, axis),
periods=(False, False), reorder=True)
Then the methods are applied to the cart object.
cart.Get_topo(...)
cart.Get_cart_rank(...)
cart.Get_coords(...)
cart.Shift(...)
See: help(MPI.Cartcomm)
There is an example cartesian.py.
Hybrid MPI and OpenMP
With Python this would be tricker (but not impossible to do). You can instead create threads in Python with the
multiprocessing module. The MPI implementation you use would need to support the threading method you want.
Basically the following can be suggested:
- When calling OpenMP (or other threads) from within an MPI task it should be perfectly safe. MPI task is just a process.
- When calling MPI from within an OpenMP thread it will depend on MPI implementation and thread safety of the MPI task.
The levels of threading in MPI is described with:
MPI_THREAD_SINGLE - only one thread will execute MPI commands.
MPI_THREAD_FUNNELED - the process may be multi-threaded but only the main thread will make MPI calls.
MPI_THREAD_SERIALIZED - the process may be multi-threaded and multiple threads may make MPI calls, but only one at a
time.
MPI_THREAD_MULTIPLE - multiple threads may cal MPI, with no restrictions.
mpi4py calld MPI_Init_thread requesting MPI_THREAD_MULTIPLE. The MPI implementation tries to fulfil that but can
provide a different level of threading support but closed to the requested level.
This really only becomes a concern when writing MPI with C and Fortran.
Key Points
MPI can deliver efficient disk I/O if designed
Providing MPI with some knowledge of topology can make MPI do all the hard work.
The different ways threads can work with MPI dictates how you can use MPI and OpenMP together.
Summary
Overview
Teaching: 5 min
Exercises: 0 minQuestions
Where can I go for further information?
Objectives
Know where to look.
Summary
This course has hopefully introduced the topic of MPI and its features. There is however many aspects not coverred such as:
- dynamic process management
- one-sided communication
- persistent communications
As mentioned in the introduction, MPI is a large standard but to get useful work done it only requires a small subset of calls. Just be aware of the whole range of features in case its useful in your application.
Key Points
MPI is supported in C, Fortran and therefore can be called from many other languages including Python.
Just need to know the translation to the other language.